Getting started \ CNES Topics
 At CNES, there are several awesome services that will help you to either develop or contribute to a library,
launch processing chains at every scale, access to massive datasets or even put your code into production.
This page gives an overview of the most important ones and links to some documentation and tips.
At CNES, there are several awesome services that will help you to either develop or contribute to a library,
launch processing chains at every scale, access to massive datasets or even put your code into production.
This page gives an overview of the most important ones and links to some documentation and tips.
Prerequisite: Scientific Information System account creation
First thing first: some of these services are accessible with a default enterprise account (default to CNES agent, not necessarily to contractors), but many also require to have a SIS account, that must be asked by a CNES agent through our enterprise ticketing system.
Software factory
Any development project needs a version control system and associated Continuous Integration (CI). At CNES a full team is dedicated to provide such an environment built on top of Gitlab and Artifactory for the most part. Full documentation of all this tooling can be found here.

Gitlab and CI
Gitlab is a service accessible to any people with an enterprise or SIS account. It is accessible at: https://gitlab.cnes.fr from inside or outside CNES facilities. From outside, there are some tricks to follow to properly access this gitlab with SSH protocol. From inside CNES network, this is just gitlab as you now it.
Continuous Integration is now handled by gitlab runners. It's pretty well documented in the Software factory documentation, just beware, for the time being, default shared runners do not have access to Computing Center environment, you'll need a project runner for this. There is one available for Data Campus division.
Artifactory: Package repository
The Artifactory package repository enables two things:
- Proxying pip, conda, docker and other public packages repository, allowing fast and easy access to these repo from CNES infrastructures
- Storing your own packages built with those technologies for internal sharing.
When working from a CNES infrastructure like our HPC system, the first thing is often to generate credentials for automatically using this service, especially when working with Python environments or Docker.
See the Pluto Trex tip explaining this shortly, more information can be found in Software factory documentation.
Computing Center
CNES Computing center offers a set of coherent services around computing and data processing at scale. It comprises an HPC (or HPDA) system, an associated Datalake, and Jupyterhub service on top of it for interactive development. These services are described in Confluence, and HPDA part also have its own complete documentation.
Datalabs for interactive analysis
The Datalabs is a custom Jupyterhub, enabling users with a SIS account to access computing power through Jupyter notebooks. It is based on the Pangeo stack, and is accessible at
- https://jupyterhub.sis.cnes.fr from inside CNES network,
- https://jupyterhub.cnes.fr from outside CNES network.
A complete documentation is also available from our Confluence instance.
It comes with prebaked Virtual Research Environment (VRE) which contains all the necessary libraries and toolset for easy development experience. But you can also use it with your own environments.
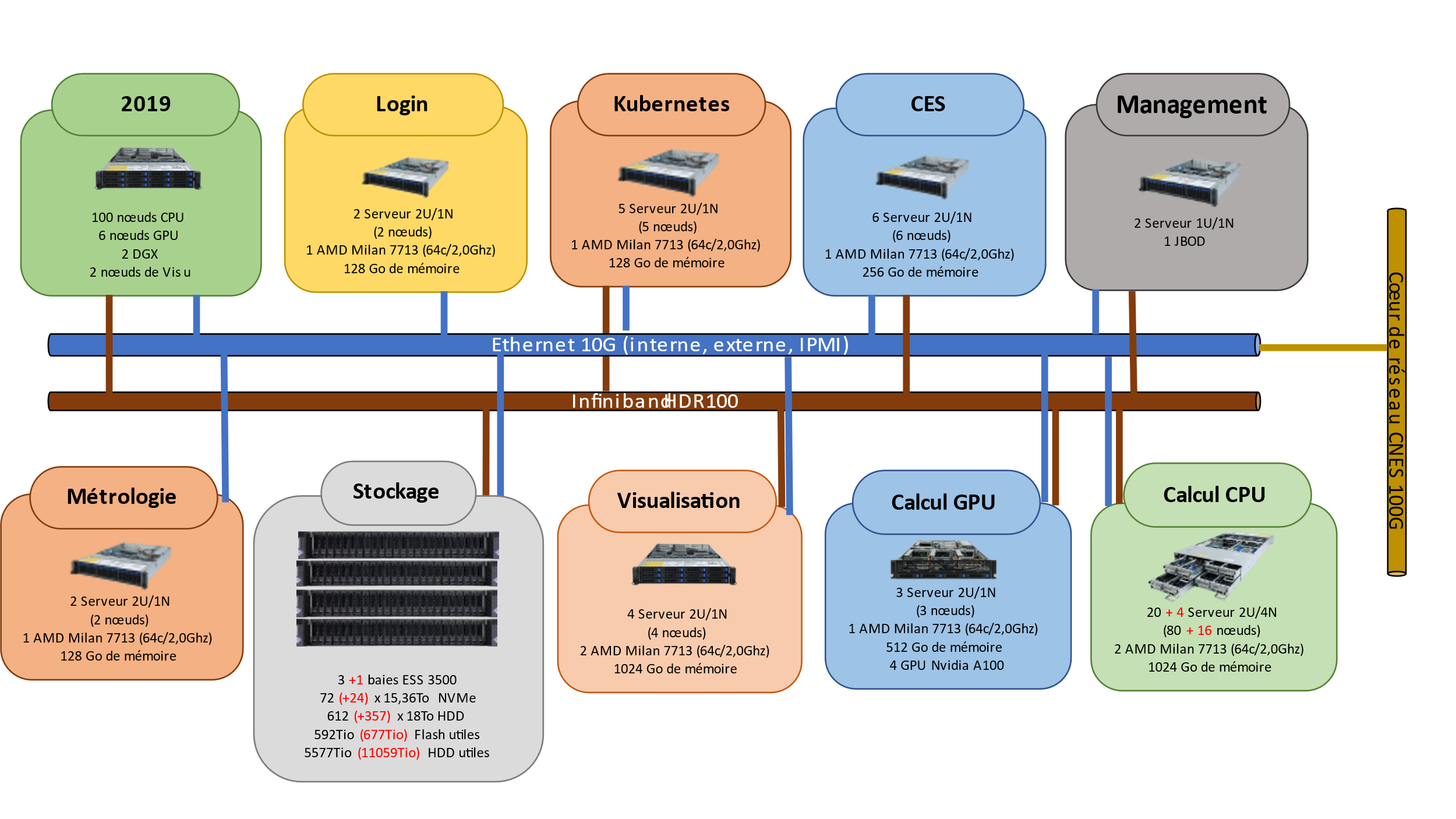
HPDA Platform: Trex
Trex is a modern HPC system, with boosted storage and GPU access, which makes it a High Performance Data Analitycs (HPDA) system. It provides access to computing resources through Slurm scheduling system, and a Spectrum Scale storage platform.
It can be accessed with an SIS account through the Datalabs, or using standard SSH access, optionnaly using VNC protocol, at:
- trex.sis.cnes.fr from inside cnes network,
- trex.cnes.fr from outside.
Other HPC platforms exist for more confidential data and algorithms.
Datalake storage platform
Three tiers of storage can be found at CNES:
- Hot storage, which is the one directly provided by the HPDA platform, based on Spectrum Scale technology with NVMe and spinning drives,
- Warm storage, based on S3 protocol on spinning hard drives,
- Cold storage, also accessible with S3 protocol, but with tapes backend.
The Datalake infrastructure provides second and third spaces above, with a unified S3 API. Main documentation of this service can be found on our Confluence instance.
It is mainly used to store public collections like a mirror of Sentinel 1 and 2 datasets from Copernicus, and also all the data produced by our own production centers, like Hydrology products (Surf Water, Let it Snow) which we talk about below.
On site data collections
CNES hosts several data collections. They are made available to the public through public portals described at Data Hub page, mainly Theia, Geodes, and Hydroweb.next.
When working on CNES infrastructure, it is important to note that every product hosted at CNES are directly accessible to users through standard POSIX or S3 interfaces. The S3 paths for every product will soon be available directly in the associated catalogs. Meanwhile, you can find products on Datalake S3 buckets:
flatsim
hydroweb
hysope2-cog
muscate
postel
sentinel1-grd
sentinel1-l2b-sw-single-sprid
sentinel1-l3b-sw-monthly-sprid
sentinel1-l3b-sw-yearly-sprid
sentinel1-ocn
sentinel1-s2l1c-sprid
sentinel1-slc
sentinel2-l1b
sentinel2-l1c
sentinel2-l2a-grs-sprid
sentinel2-l2a-peps
sentinel2-l2a-sprid
sentinel2-l2b-obs2co-sprid
sentinel2-l2b-snow-sprid
sentinel2-l2b-sw-single-sprid
sentinel2-l3a-sprid
sentinel2-l3b-snow-sprid
sentinel2-l3b-sw-monthly-sprid
sentinel2-l3b-sw-yearly-sprid
sentinel3-sral
sentinel6-l1a
swh-l1a
take5
On HPC system storage, there is also a /work/datalake hosting some interesting data. One really useful is
/work/datalake/static_aux/, with predownloaded auxiliary data like MNT.
Other services
CNES IT teams also provide a lot of other services which can be useful, but more when developing a full service or a production center:
- Virtual machines,
- Mutualised Kubernetes cluster,
- NAS Storage,
- Management tools like Confluence and JIRA.
And plenty others.